CVPR 2023
Unite and Conquer: Plug and Play Multimodal Synthesis using Diffusion Models
Abstract
Generating photos satisfying multiple constraints finds broad utility in the content creation industry. A key hurdle to accomplishing this task is the need for paired data consisting of all modalities (i.e., constraints) and their corresponding output. Moreover, existing methods need retraining using paired data across all modalities to introduce a new condition. This paper proposes a solution to this problem based on denoising diffusion probabilistic models (DDPMs). Our motivation for choosing diffusion models over other generative models comes from the flexible internal structure of diffusion models. Since each sampling step in the DDPM follows a Gaussian distribution, we show that there exists a closed-form solution for generating an image given various constraints. Our method can unite multiple diffusion models trained on multiple sub-tasks and conquer the combined task through our proposed sampling strategy. We also introduce a novel reliability parameter that allows using different off-the-shelf diffusion models trained across various datasets during sampling time alone to guide it to the desired outcome satisfying multiple constraints. We perform experiments on various standard multimodal tasks to demonstrate the effectiveness of our approach.
Our model can combine task spectific information learned by multiple models and perform composite generation during inference time without any explciit retraining.
Method
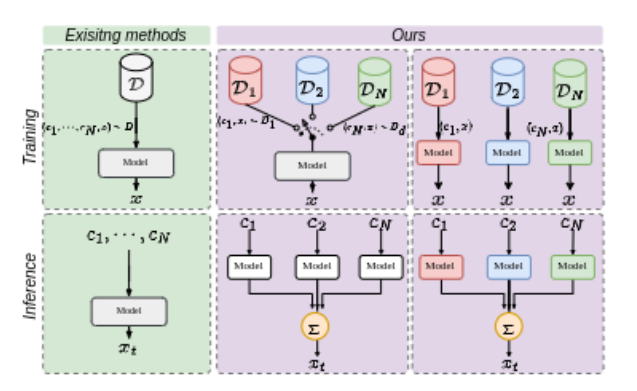
Our model can combine task spectific information learned by multiple models and perform composite generation during inference time without any explciit retraining.
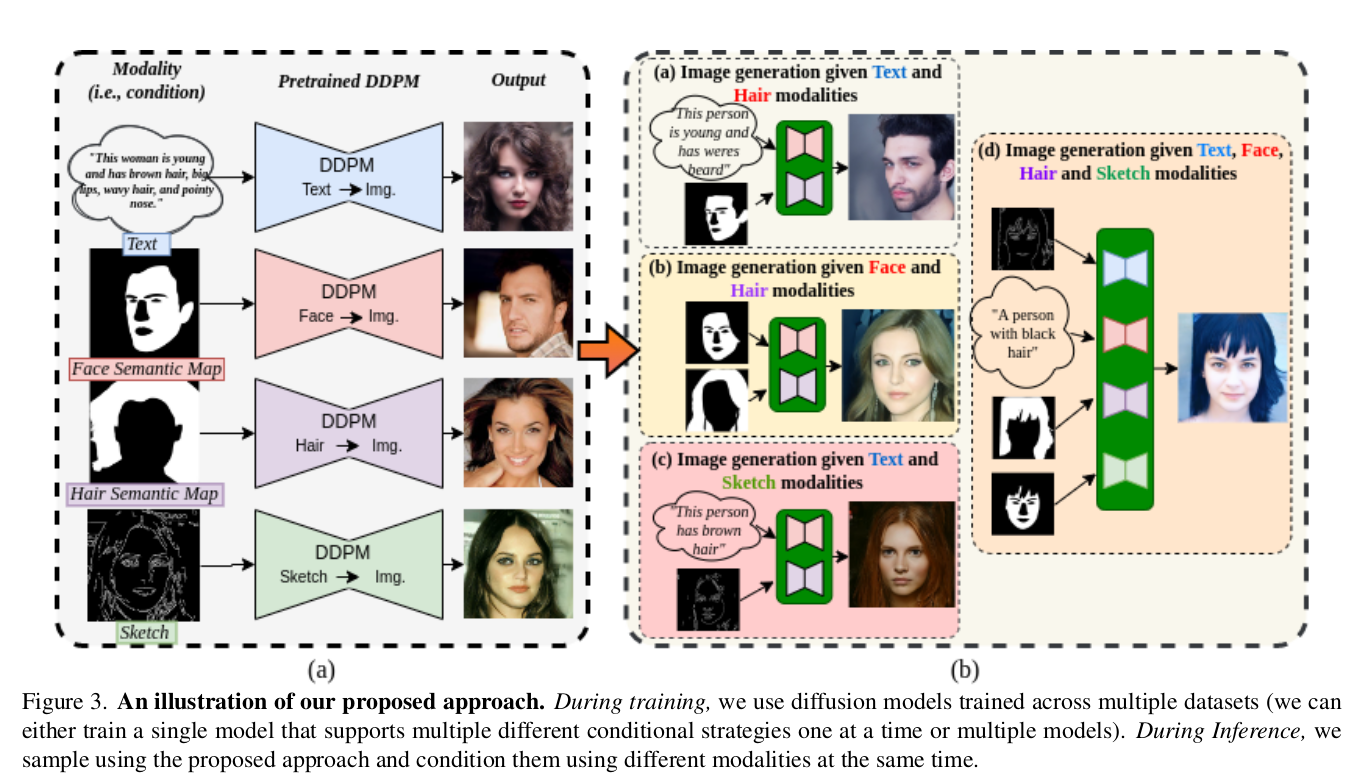
Multimodal face generation
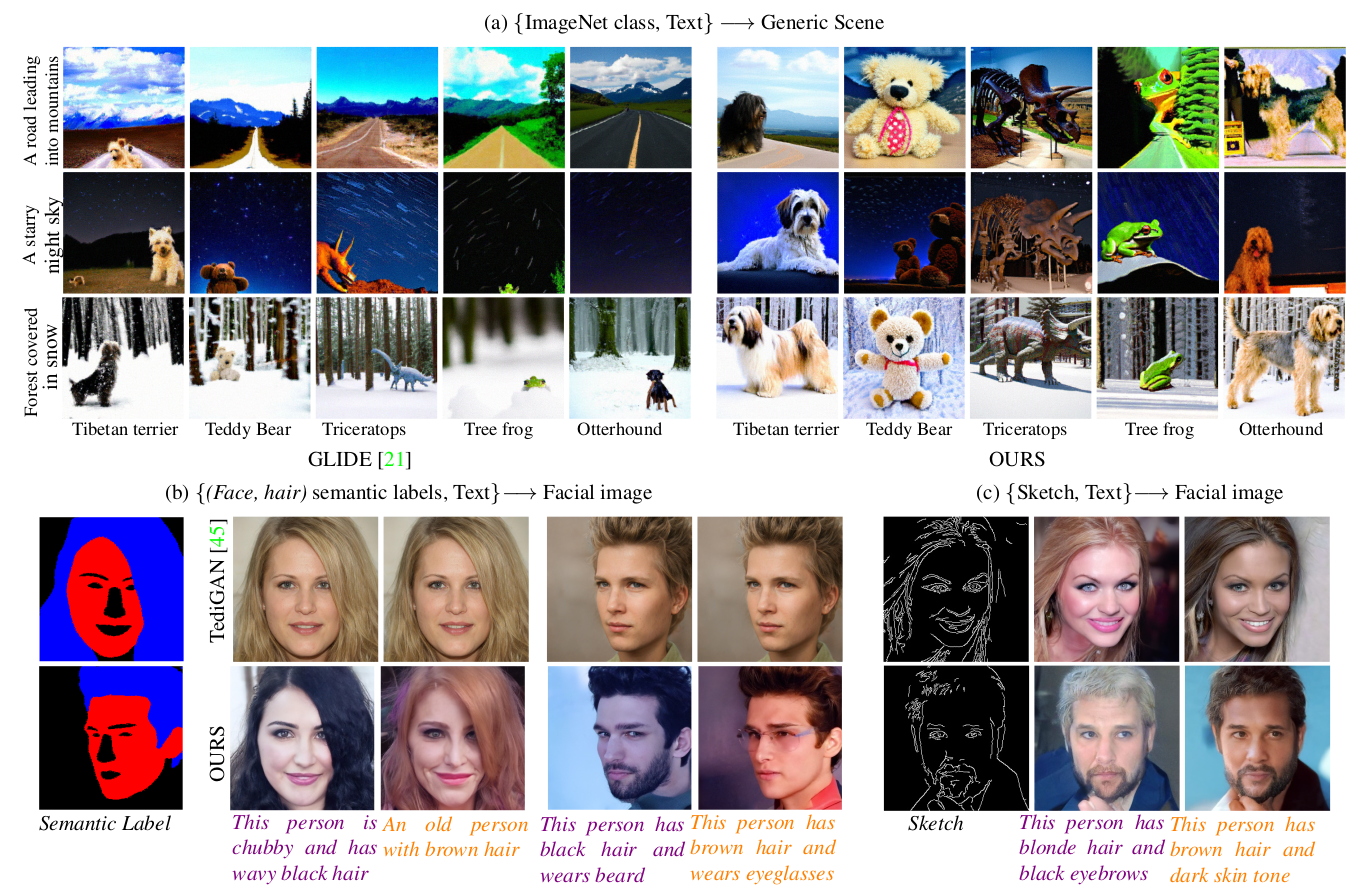
Multimodal generic scenes generation

Multimodal Interpolation

Video Explanation
Citation
@article{nair2023unite,
title={Unite and Conquer: Plug \& Play Multi-Modal Synthesis Using Diffusion Models},
author={Nair, Nithin Gopalakrishnan and Bandara, Wele Gedara Chaminda and Patel, Vishal M},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6070--6079},
year={2023}
}