Nithin Gopalakrishnan Nair

I am a Research Engineer at Apple, where I develop agentic workflows for human interaction understanding. I completed my Ph.D. in Electrical and Computer Engineering at Johns Hopkins University, working under the supervision of Dr. Vishal M. Patel at the VIU Lab. Prior to JHU, I obtained my dual degree (B.Tech & M.Tech) in Electrical Engineering from the Indian Institute of Technology Madras, where I conducted research on image reconstruction with Dr. A.N. Rajagopalan at the IPCV Lab.
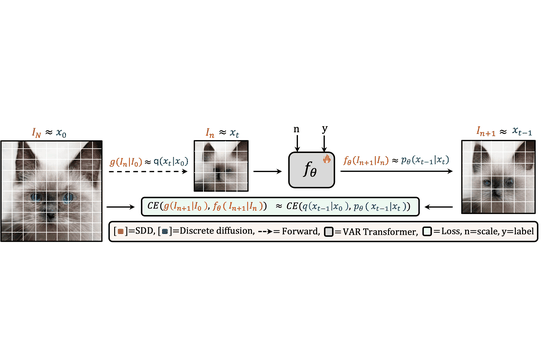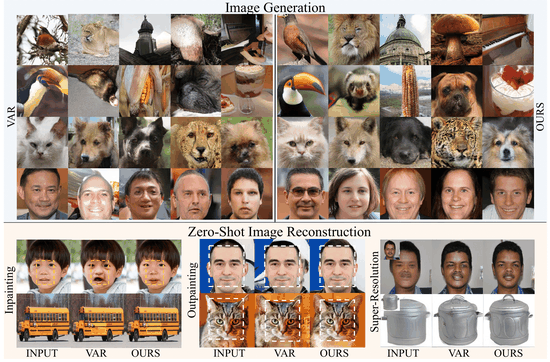
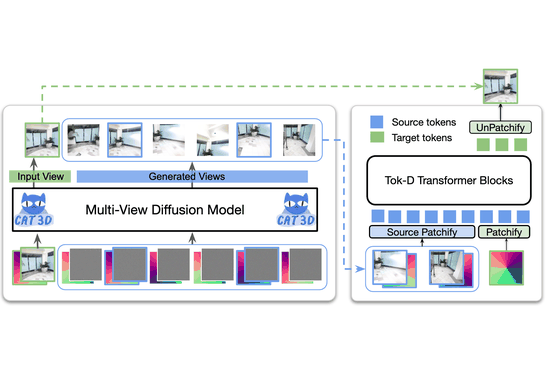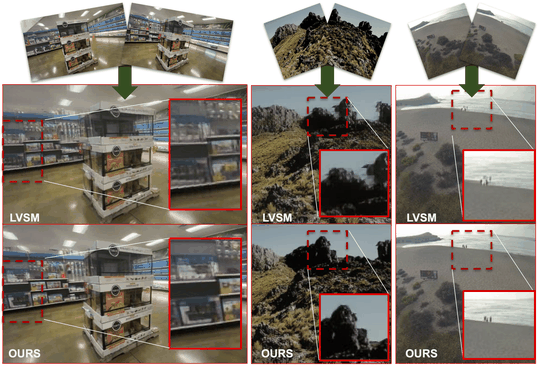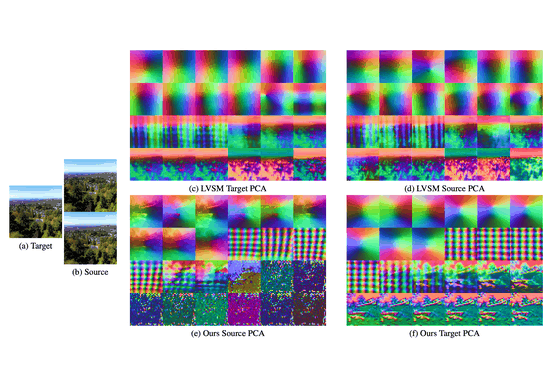
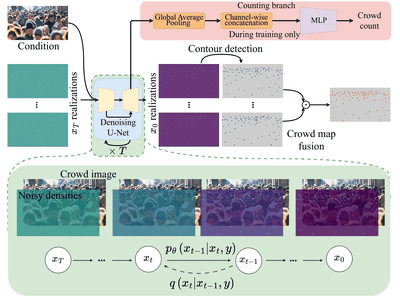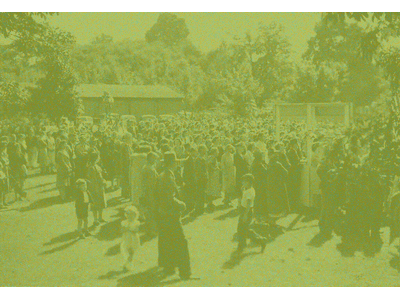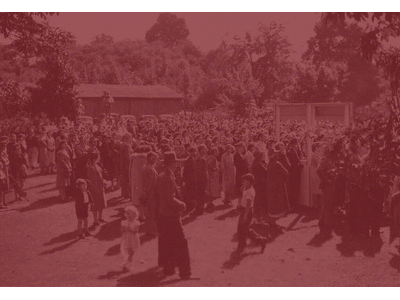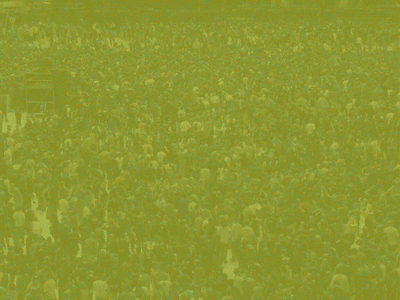
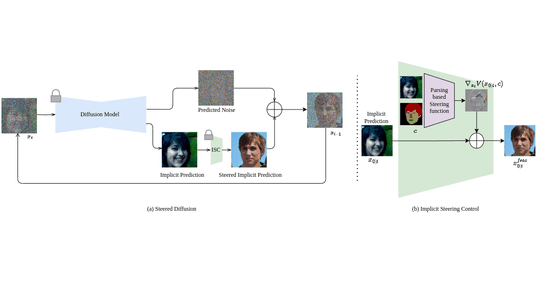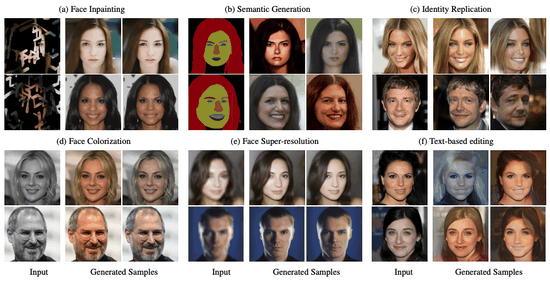
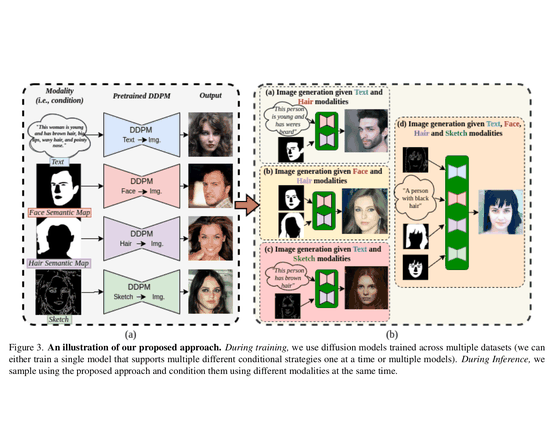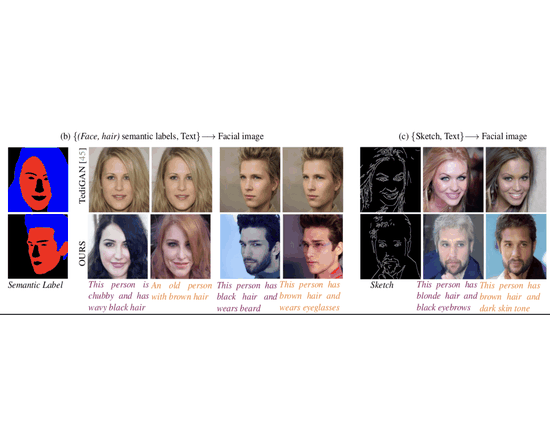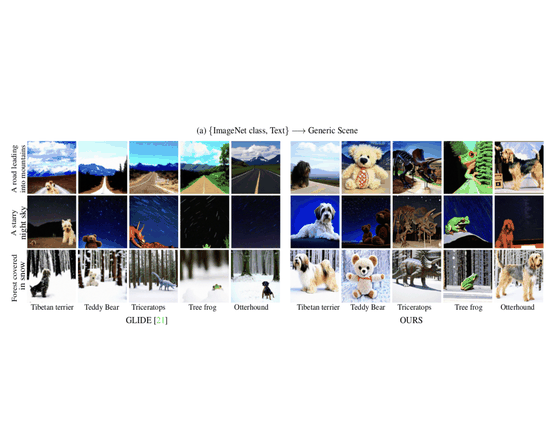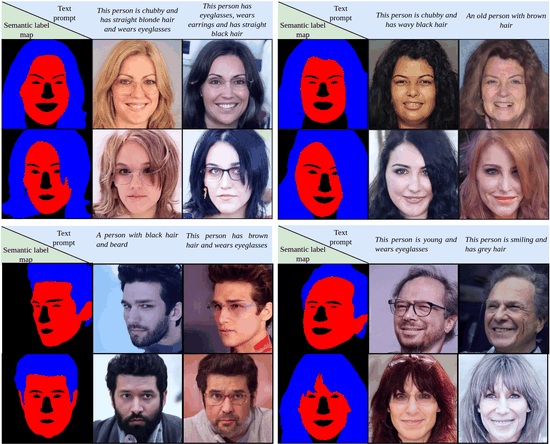
My PhD research focused on computer vision, with an emphasis on deep generative modeling. This included work on diffusion models, plug-and-play architectures, and efficient generation techniques for resource-constrained devices.
I find the theory behind diffusion models fascinating. Fun fact: the basics were proposed by Einstein! Over the past several years, I have contributed to advances in image, video, and 3D generation using these models. I welcome collaborations with researchers who share an interest in generative modeling. Please feel free to reach out.