
Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-to-end with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning.
Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess. We show the effectiveness of our method by utilizing off-the-shelf models for multi-modal generation. We will make the code public after the review process.
We visualize variance Maps across channels for intermediate features of ControlNet for different modalities. As we can see the variance map has high values where the condition is present and has low values for locations where the condition is absent.

Figure illustrating variance maps of intermediate features of encoder and decoder for the text prompt "An astronaut riding a horse" for the 5th timestep of diffusion.

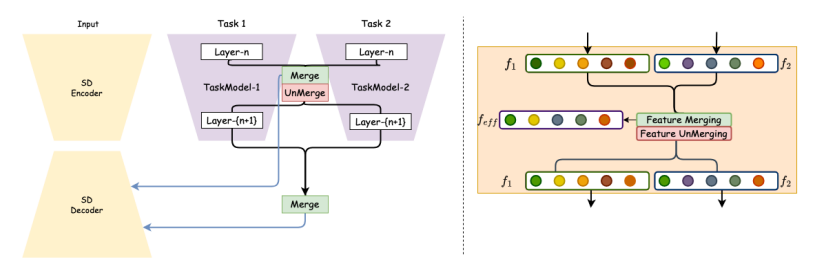
An illustration of MaxFusion. During the progression through the Text to Image Model, intermediate features are consolidated at each location, and the resulting merged features are subsequently transmitted to the diffusion module. Please note the colors during the merging and unmerging operation. Similar features are not unmerged and are passed as such to the next network layer. Non-similar intermediate outputs are passed without any change.
Qualitative comparisons for contradictory conditions from different modalities. Figure illustrates the case of different conditions where out method shows a clear advantage over existing approaches. The text prompts used are (1): "Walter White in a living room, GTA style." (2) "A bicycle in a garden." (3) "A car in front of arc de triomphe"

Qualitative comparisons for complimentary conditions in COCO dataset. For the unimodal models we condition with its corresponding conditions. For multimodal models, we condition using both the Tasks. The text prompts used for conditioning are: from top (1): "A banana sitting on a chair and looking at the beach." (2) "A brocolli in a hand." (3) "A blackboard and table in a classroom" (4) "A couple of sheep standing"

@article{nair2024maxfusion,
title={MaxFusion: Plug\&Play Multi-Modal Generation in Text-to-Image Diffusion Models},
author={Nair, Nithin Gopalakrishnan and Valanarasu, Jeya Maria Jose and Patel, Vishal M},
journal={arXiv preprint arXiv:2404.09977},
year={2024}
}