Publications
2025
- arXiv 2025
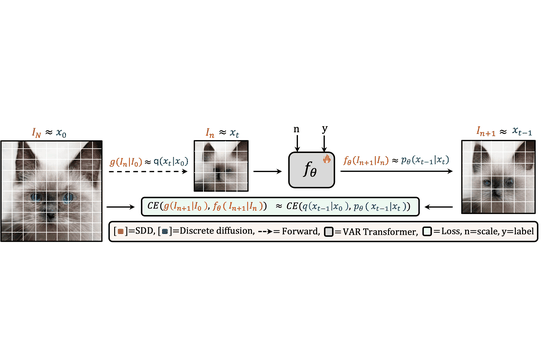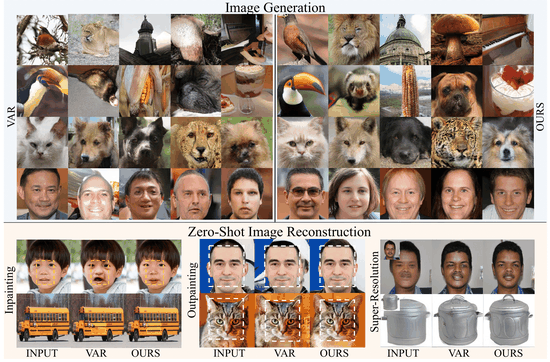 Scale-wise VAR is Secretly Discrete DiffusionAmandeep Kumar*, Nithin Gopalakrishnan Nair*, and Vishal M PatelarXiv preprint arXiv:2509.22636, 2025
Scale-wise VAR is Secretly Discrete DiffusionAmandeep Kumar*, Nithin Gopalakrishnan Nair*, and Vishal M PatelarXiv preprint arXiv:2509.22636, 2025Visual Autoregressive (VAR) models have recently emerged as a powerful alternative to diffusion models for high-quality image generation. The VAR architecture generates visual tokens in a coarse-to-fine, scale-by-scale manner, which sets it apart from traditional raster-order autoregressive models. However, the inner mechanism behind VAR model’s effectiveness is under-explored. In this paper, we present a novel perspective on VAR: we show that VAR models can be viewed through the lens of discrete diffusion models. Specifically, we demonstrate that VAR’s generative process is functionally equivalent to a scale-wise discrete masked diffusion process, with slight variation in the learning objective. In this framework, VAR’s next-scale predictions correspond to masked token recovery in a multi-scale latent space. Our findings reveal a deep connection between autoregressive visual generation and diffusion processes, offering new theoretical insights and opening the door for further exploration of hybrid generative architectures.
@article{kumar2025scale, title = {Scale-wise VAR is Secretly Discrete Diffusion}, author = {Kumar, Amandeep and Nair, Nithin Gopalakrishnan and Patel, Vishal M}, journal = {arXiv preprint arXiv:2509.22636}, year = {2025}, } - ICCV 2025
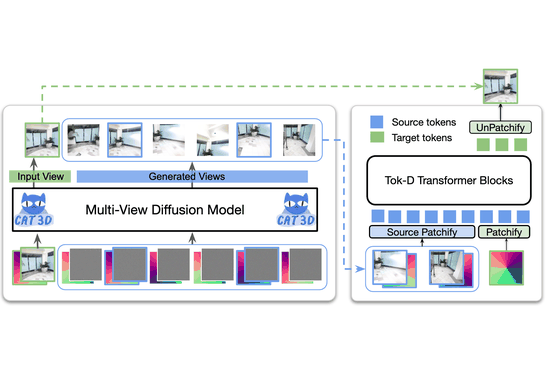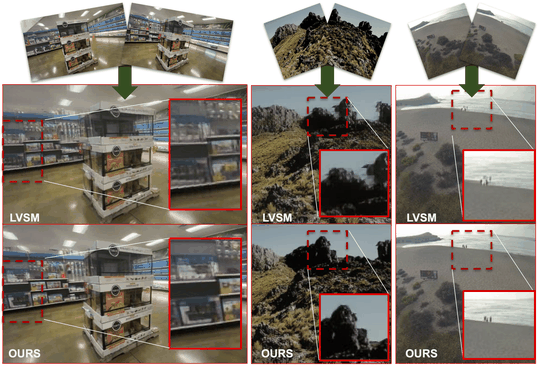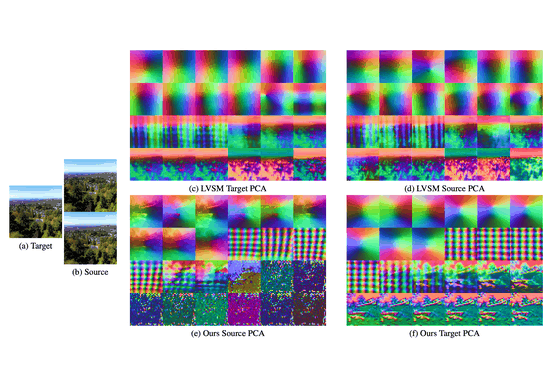 Scaling Transformer-Based Novel View Synthesis with Models Token Disentanglement and Synthetic DataNithin Gopalakrishnan Nair, Srinivas Kaza, Xuan Luo, and 3 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025
Scaling Transformer-Based Novel View Synthesis with Models Token Disentanglement and Synthetic DataNithin Gopalakrishnan Nair, Srinivas Kaza, Xuan Luo, and 3 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025Large transformer-based models have made significant progress in generalizable novel view synthesis (NVS) from sparse input views, generating novel viewpoints without the need for test-time optimization. However, these models are constrained by the limited diversity of publicly available scene datasets, making most real-world (in-the-wild) scenes out-of-distribution. To overcome this, we incorporate synthetic training data generated from diffusion models, which improves generalization across unseen domains. While synthetic data offers scalability, we identify artifacts introduced during data generation as a key bottleneck affecting reconstruction quality. To address this, we propose a token disentanglement process within the transformer architecture, enhancing feature separation and ensuring more effective learning. This refinement not only improves re-construction quality over standard transformers but also enables scalable training with synthetic data. As a result, our method outperforms existing models on both in-dataset and cross-dataset evaluations, achieving state-of-the-art results across multiple benchmarks while significantly reducing computational costs
@inproceedings{nair2025scaling, title = {Scaling Transformer-Based Novel View Synthesis with Models Token Disentanglement and Synthetic Data}, author = {Nair, Nithin Gopalakrishnan and Kaza, Srinivas and Luo, Xuan and Patel, Vishal M and Lombardi, Stephen and Park, Jungyeon}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages = {28567--28576}, year = {2025}, archiveprefix = {arXiv}, primaryclass = {cs.GR}, selected = true, eprint = {2509.06950}, url = {https://scaling3dnvs.github.io/}, } - WACV 2025
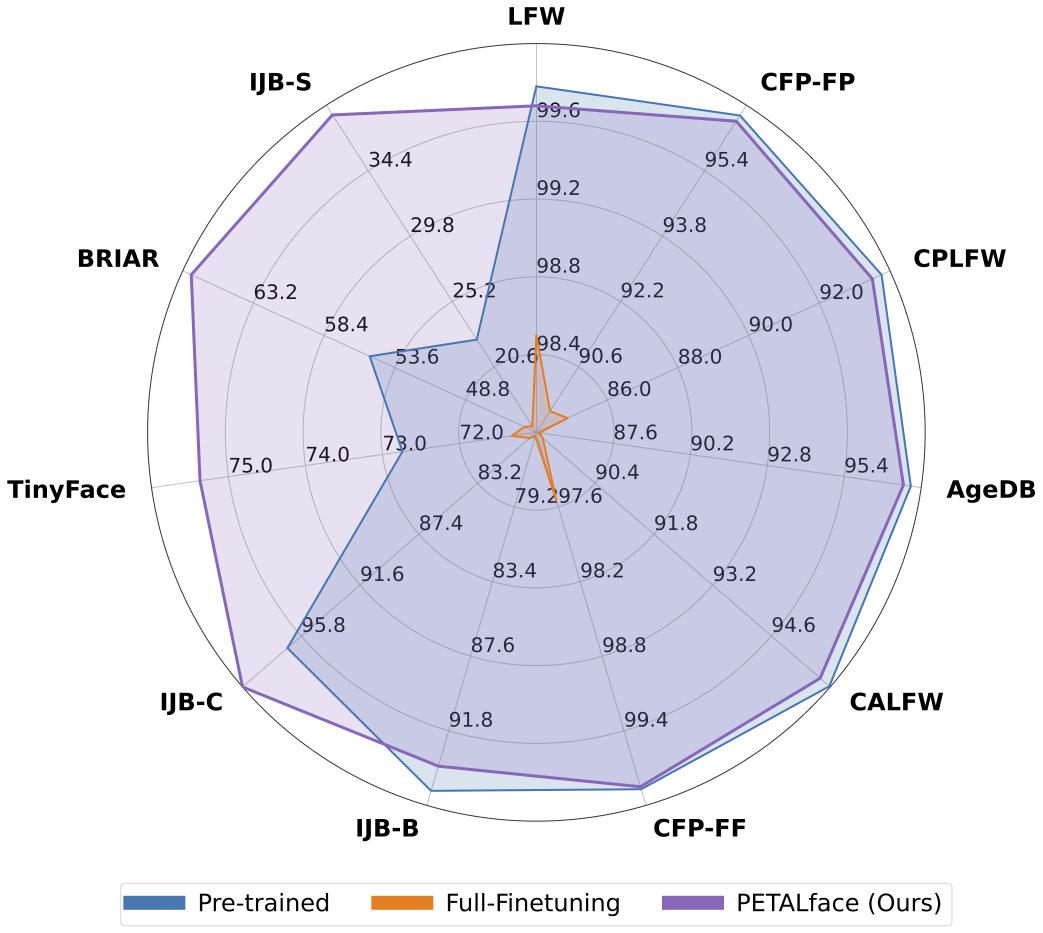 PETALface: Parameter Efficient Transfer Learning for Low-resolution Face RecognitionKartik Narayan, Nithin Gopalakrishnan Nair, Jennifer Xu, and 2 more authorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
PETALface: Parameter Efficient Transfer Learning for Low-resolution Face RecognitionKartik Narayan, Nithin Gopalakrishnan Nair, Jennifer Xu, and 2 more authorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025Pre-training on large-scale datasets and utilizing margin-based loss functions have been highly successful in training models for high-resolution face recognition. However, these models struggle with low-resolution face datasets, in which the faces lack the facial attributes necessary for distinguishing different faces. Full fine-tuning on low-resolution datasets, a naive method for adapting the model, yields inferior performance due to catastrophic forgetting of pre-trained knowledge. Additionally, the domain difference between high-resolution gallery images and low-resolution probe images leads to poor convergence. To address these issues, we propose PETALface, a Parameter-Efficient Transfer Learning approach for low-resolution face recognition. We utilize low-rank adaptation of attention layers to adapt the pretrained model to low-resolution datasets. We introduce two low-rank adaptation modules that are constrained during training and act as separate proxy encoders for high-resolution and low-resolution data, respectively. Extensive experiments demonstrate that PETALface outperforms full fine-tuning on low-resolution datasets while preserving performance on high-resolution and mixed-quality datasets, using only 0.48% of the parameters.
@inproceedings{narayan2025petalface, title = {PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition}, author = {Narayan, Kartik and Nair, Nithin Gopalakrishnan and Xu, Jennifer and Chellappa, Rama and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, year = {2025}, url = {https://kartik-3004.github.io/PETALface/}, } - FG 2025
 Improved Representation Learning for Unconstrained Face RecognitionNithin Gopalakrishnan Nair, Kartik Narayan, Maitreya Suin, and 7 more authorsIn 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG), 2025
Improved Representation Learning for Unconstrained Face RecognitionNithin Gopalakrishnan Nair, Kartik Narayan, Maitreya Suin, and 7 more authorsIn 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG), 2025Face recognition is a widely studied problem where the aim is to design a robust network that assigns higher similarity to the same face and reduces similarity between dissimilar faces. We address low-quality face recognition by reconsidering model choice, data input pipeline and fine-tuning schemes rather than solely focusing on loss functions. We achieve state-of-the-art results on medium and challenging benchmarks including IJB-B, IJB-C, Tinyface, IJB-S, and BRIAR.
@inproceedings{nair2025improved, title = {Improved Representation Learning for Unconstrained Face Recognition}, author = {Nair, Nithin Gopalakrishnan and Narayan, Kartik and Suin, Maitreya and Kathirvel, Ram Prabhakar and Xu, Jennifer and Stevens, Soraya and Gleason, Joshua and Shnidman, Nathan and Chellappa, Rama and Patel, Vishal M}, booktitle = {2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG)}, year = {2025}, doi = {10.1109/FG61629.2025.11099270}, } - CVPR 2025
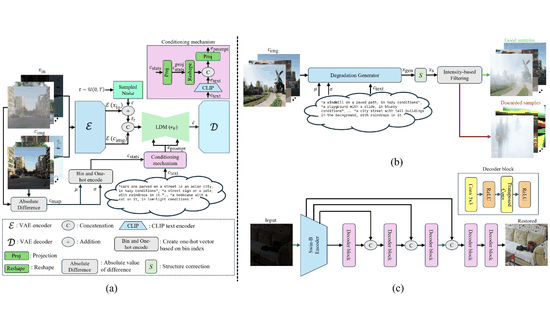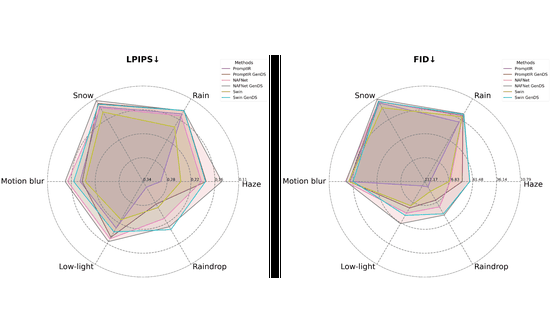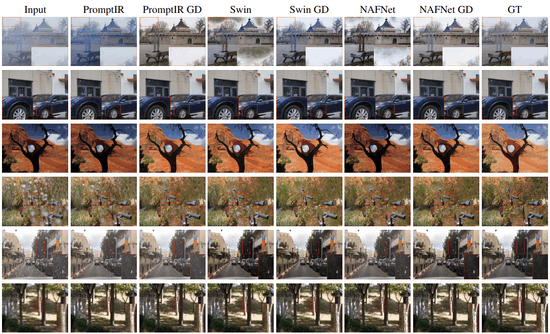 GenDeg: Diffusion-based Degradation Synthesis for Generalizable All-in-One Image RestorationSudarshan Rajagopalan, Nithin Gopalakrishnan Nair, Jay N Paranjape, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
GenDeg: Diffusion-based Degradation Synthesis for Generalizable All-in-One Image RestorationSudarshan Rajagopalan, Nithin Gopalakrishnan Nair, Jay N Paranjape, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025Deep learning-based models for All-In-One image Restoration (AIOR) have achieved significant advancements in recent years. However, their practical applicability is limited by poor generalization to samples outside the training distribution. This limitation arises primarily from insufficient diversity in degradation variations and scenes within existing datasets. In this paper, we leverage the generative capabilities of latent diffusion models to synthesize high-quality degraded images from their clean counterparts. Specifically, we introduce GenDeg, a degradation and intensity-aware conditional diffusion model, capable of producing diverse degradation patterns on clean images. Using GenDeg, we synthesize over 550k samples across six degradation types: haze, rain, snow, motion blur, low-light, and raindrops. These generated samples are integrated with existing datasets to form the GenDS dataset, comprising over 750k samples. Our experiments reveal that image restoration models trained on GenDS dataset exhibit significant improvements in out-of-distribution performance.
@inproceedings{rajagopalan2025gendeg, title = {GenDeg: Diffusion-based Degradation Synthesis for Generalizable All-in-One Image Restoration}, author = {Rajagopalan, Sudarshan and Nair, Nithin Gopalakrishnan and Paranjape, Jay N and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {28144--28154}, year = {2025}, selected = true, url = {https://sudraj2002.github.io/gendegpage/}, } - WACV 2025
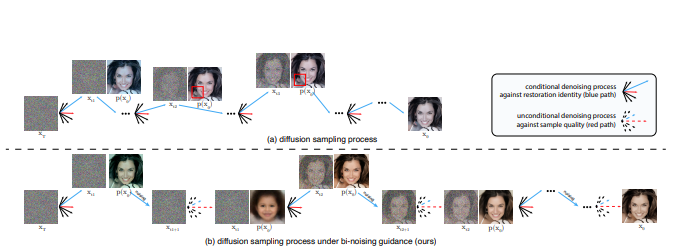 Bi-Noising Diffusion: Towards Conditional Diffusion Models with Generative Restoration PriorsKangfu Mei, Nithin Gopalakrishnan Nair, and Vishal M Patel2025
Bi-Noising Diffusion: Towards Conditional Diffusion Models with Generative Restoration PriorsKangfu Mei, Nithin Gopalakrishnan Nair, and Vishal M Patel2025Conditional diffusion probabilistic models can model the distribution of natural images and can generate diverse and realistic samples based on given conditions. However, oftentimes their results can be unrealistic with observable color shifts and textures. We believe that this issue results from the divergence between the probabilistic distribution learned by the model and the distribution of natural images. The delicate conditions gradually enlarge the divergence during each sampling timestep. To address this issue, we introduce a new method that brings the predicted samples to the training data manifold using a pretrained unconditional diffusion model. The unconditional model acts as a regularizer and reduces the divergence introduced by the conditional model at each sampling step. We perform comprehensive experiments to demonstrate the effectiveness of our approach on super-resolution, colorization, turbulence removal, and image-deraining tasks. The improvements obtained by our method suggest that the priors can be incorporated as a general plugin for improving conditional diffusion models. Our demo is https://kfmei.page/bi-noising/
@article{mei2022bi, title = {Bi-Noising Diffusion: Towards Conditional Diffusion Models with Generative Restoration Priors}, author = {Mei, Kangfu and Nair, Nithin Gopalakrishnan and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, } - WACV 2025
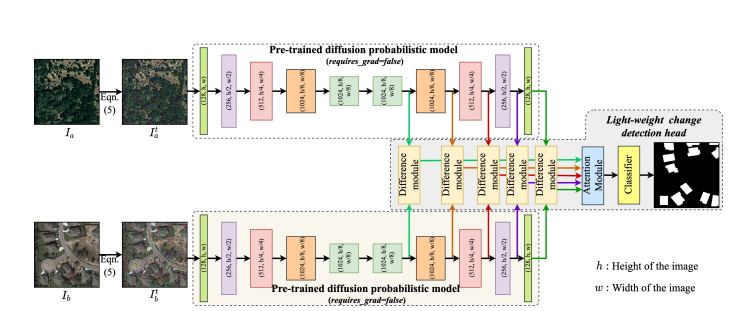 DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic ModelsWele Gedara Chaminda Bandara, Nithin Gopalakrishnan Nair, and Vishal M Patel2025
DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic ModelsWele Gedara Chaminda Bandara, Nithin Gopalakrishnan Nair, and Vishal M Patel2025Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts. To this end, observing precisely defined changes on Earth’s surface is essential, and we propose an effective way to achieve this goal. Notably, our change detection (CD) method proposes a novel way to incorporate the millions of off-the-shelf, unlabeled, remote sensing images available through different earth observation programs into the training process through denoising diffusion probabilistic models. We first leverage the information from these off-the-shelf, uncurated, and unlabeled remote sensing images by using a pre-trained denoising diffusion probabilistic model and then employ the multi-scale feature representations from the diffusion model decoder to train a lightweight CD classifier to detect precise changes. The experiments performed on four publically available CD datasets show that the proposed approach achieves remarkably better results than the state-of-the-art methods in F1, IoU and overall accuracy. Code and pre-trained models are available at: https : //github.com/wgcban/ddpm − cd
@article{bandara2022ddpm, title = {DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic Models}, author = {Bandara, Wele Gedara Chaminda and Nair, Nithin Gopalakrishnan and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, }
2024
- ECCV 2024
 Maxfusion: Plug&play multi-modal generation in text-to-image diffusion modelsNithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, and Vishal M PatelIn European Conference on Computer Vision, 2024
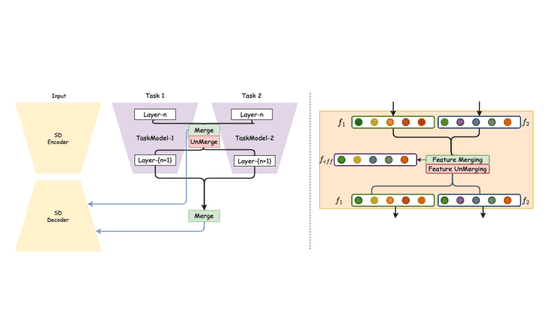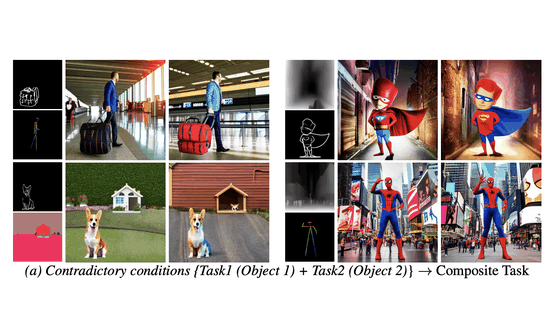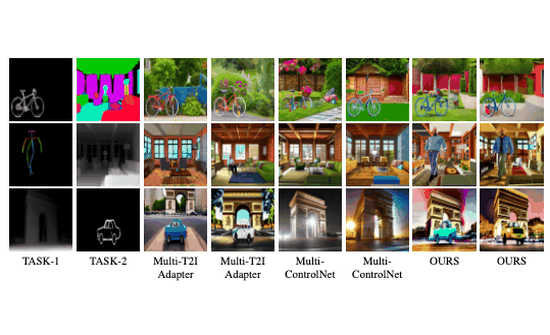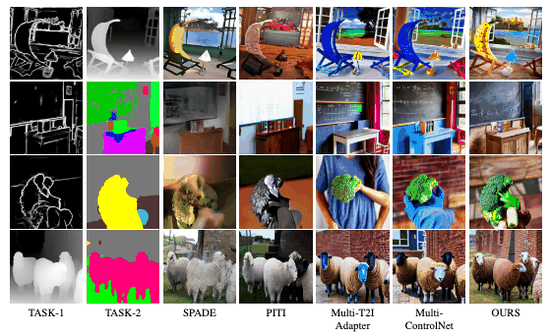
Maxfusion: Plug&play multi-modal generation in text-to-image diffusion modelsNithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, and Vishal M PatelIn European Conference on Computer Vision, 2024Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-to-end with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess. We show the effectiveness of our method by utilizing off-the-shelf models for multi-modal generation.
@inproceedings{nair2025maxfusion, title = {Maxfusion: Plug\&play multi-modal generation in text-to-image diffusion models}, author = {Nair, Nithin Gopalakrishnan and Valanarasu, Jeya Maria Jose and Patel, Vishal M}, booktitle = {European Conference on Computer Vision}, pages = {93--110}, year = {2024}, selected = true, } - CVPR 2024
 Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion ModelsYasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Mar 2024
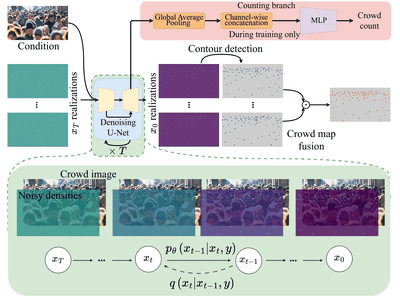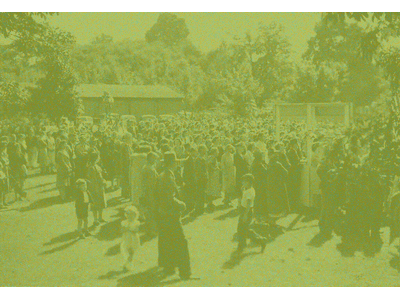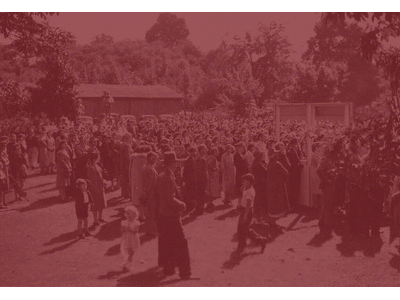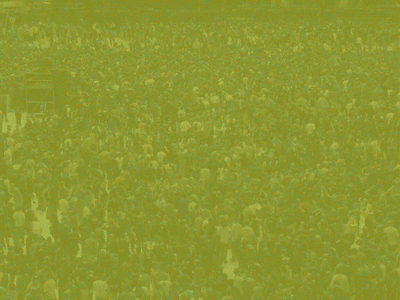
Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion ModelsYasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Mar 2024Crowd counting is a key aspect of crowd analysis and has been typically accomplished by estimating a crowd density map and summing over the density values. However, this approach suffers from background noise accumulation and loss of density due to the use of broad Gaussian kernels to create the ground truth density maps. This issue can be overcome by narrowing the Gaussian kernel. However, existing approaches perform poorly when trained with such ground truth density maps. To overcome this limitation, we propose using conditional diffusion models to predict density maps, as diffusion models are known to model complex distributions well and show high fidelity to training data during crowd-density map generation. Furthermore, as the intermediate time steps of the diffusion process are noisy, we incorporate a regression branch for direct crowd estimation only during training to improve the feature learning. In addition, owing to the stochastic nature of the diffusion model, we introduce producing multiple density maps to improve the counting performance contrary to the existing crowd counting pipelines. Further, we also differ from the density summation and introduce contour detection followed by summation as the counting operation, which is more immune to background noise. We conduct extensive experiments on public datasets to validate the effectiveness of our method. Specifically, our novel crowd-counting pipeline improves the error of crowd-counting by up to 6 percent on JHU-CROWD++ and up to 7 percent on UCF-QNRF.
@inproceedings{ranasinghe2024diffuse, title = {Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion Models}, author = {Ranasinghe, Yasiru and Nair, Nithin Gopalakrishnan and Bandara, Wele Gedara Chaminda and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, month = mar, year = {2024}, url = {https://dylran.github.io/crowddiff.github.io/}, } - arXiv 2024
 Dreamguider: Improved Training free Diffusion-based Conditional GenerationNithin Gopalakrishnan Nair and Vishal M PatelarXiv preprint arXiv:2406.02549, Mar 2024
Dreamguider: Improved Training free Diffusion-based Conditional GenerationNithin Gopalakrishnan Nair and Vishal M PatelarXiv preprint arXiv:2406.02549, Mar 2024Diffusion models have emerged as a formidable tool for training-free conditional generation. However, a key hurdle in inference-time guidance techniques is the need for compute-heavy backpropagation through the diffusion network for estimating the guidance direction. Moreover, these techniques often require handcrafted parameter tuning on a case-by-case basis. Although some recent works have introduced minimal compute methods for linear inverse problems, a generic lightweight guidance solution to both linear and non-linear guidance problems is still missing. To this end, we propose Dreamguider, a method that enables inference-time guidance without compute-heavy backpropagation through the diffusion network. The key idea is to regulate the gradient flow through a time-varying factor. Moreover, we propose an empirical guidance scale that works for a wide variety of tasks, hence removing the need for handcrafted parameter tuning. We further introduce an effective lightweight augmentation strategy that significantly boosts the performance during inference-time guidance. We present experiments using Dreamguider on multiple tasks across multiple datasets and models to show the effectiveness of the proposed modules. To facilitate further research, we will make the code public after the review process.
@article{nair2024dreamguider, title = {Dreamguider: Improved Training free Diffusion-based Conditional Generation}, author = {Nair, Nithin Gopalakrishnan and Patel, Vishal M}, journal = {arXiv preprint arXiv:2406.02549}, year = {2024}, } - arXiv 2024
 Diffscaler: Enhancing the Generative Prowess of Diffusion TransformersNithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, and Vishal M PatelarXiv preprint arXiv:2404.09976, Mar 2024
Diffscaler: Enhancing the Generative Prowess of Diffusion TransformersNithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, and Vishal M PatelarXiv preprint arXiv:2404.09976, Mar 2024Recently, diffusion transformers have gained wide attention with the release of SORA from OpenAI, emphasizing the need for transformers as backbone for diffusion models. Transformer-based models have shown better generalization capability compared to CNN-based models for general vision tasks. However, much less has been explored in the existing literature regarding the capabilities of transformer-based diffusion backbones and expanding their generative prowess to other datasets. This paper focuses on enabling a single pre-trained diffusion transformer model to scale across multiple datasets swiftly, allowing for the completion of diverse generative tasks using just one model. To this end, we propose DiffScaler, an efficient scaling strategy for diffusion models where we train a minimal amount of parameters to adapt to different tasks. In particular, we learn task-specific transformations at each layer by incorporating the ability to utilize the learned subspaces of the pre-trained model, as well as the ability to learn additional task-specific subspaces, which may be absent in the pre-training dataset. As these parameters are independent, a single diffusion model with these task-specific parameters can be used to perform multiple tasks simultaneously. Moreover, we find that transformer-based diffusion models significantly outperform CNN-based diffusion models methods while performing fine-tuning over smaller datasets. We perform experiments on four unconditional image generation datasets. We show that using our proposed method, a single pre-trained model can scale up to perform these conditional and unconditional tasks, respectively, with minimal parameter tuning while performing as close as fine-tuning an entire diffusion model for that particular task.
@article{nair2024diffscaler, title = {Diffscaler: Enhancing the Generative Prowess of Diffusion Transformers}, author = {Nair, Nithin Gopalakrishnan and Valanarasu, Jeya Maria Jose and Patel, Vishal M}, journal = {arXiv preprint arXiv:2404.09976}, year = {2024}, } - MIUA 2024
 Adaptivesam: Towards efficient tuning of sam for surgical scene segmentationJay N Paranjape, Nithin Gopalakrishnan Nair, Shameema Sikder, and 2 more authorsIn Annual Conference on Medical Image Understanding and Analysis, Mar 2024
Adaptivesam: Towards efficient tuning of sam for surgical scene segmentationJay N Paranjape, Nithin Gopalakrishnan Nair, Shameema Sikder, and 2 more authorsIn Annual Conference on Medical Image Understanding and Analysis, Mar 2024Segmentation is a fundamental problem in surgical scene analysis using artificial intelligence. However, the inherent data scarcity in this domain makes it challenging to adapt traditional segmentation techniques for this task. To tackle this issue, current research employs pretrained models and finetunes them on the given data. Even so, these require training deep networks with millions of parameters every time new data becomes available. A recently published foundation model, Segment-Anything (SAM), generalizes well to a large variety of natural images, hence tackling this challenge to a reasonable extent. However, SAM does not generalize well to the medical domain as is without utilizing a large amount of compute resources for fine-tuning and using task-specific prompts. Moreover, these prompts are in the form of boundingboxes or foreground/background points that need to be annotated explicitly for every image, making this solution increasingly tedious with higher data size. In this work, we propose AdaptiveSAM - an adaptive modification of SAM that can adjust to new datasets quickly and efficiently, while enabling text-prompted segmentation. For finetuning AdaptiveSAM, we propose an approach called bias-tuning that requires a significantly smaller number of trainable parameters than SAM (less than 2%). At the same time, AdaptiveSAM requires negligible expert intervention since it uses free-form text as prompt and can segment the object of interest with just the label name as prompt. Our experiments show that AdaptiveSAM outperforms current stateof-the-art methods on various medical imaging datasets including surgery, ultrasound and X-ray.
@inproceedings{paranjape2024adaptivesam, title = {Adaptivesam: Towards efficient tuning of sam for surgical scene segmentation}, author = {Paranjape, Jay N and Nair, Nithin Gopalakrishnan and Sikder, Shameema and Vedula, S Swaroop and Patel, Vishal M}, booktitle = {Annual Conference on Medical Image Understanding and Analysis}, pages = {187--201}, year = {2024}, organization = {Springer}, } - WACV 2024
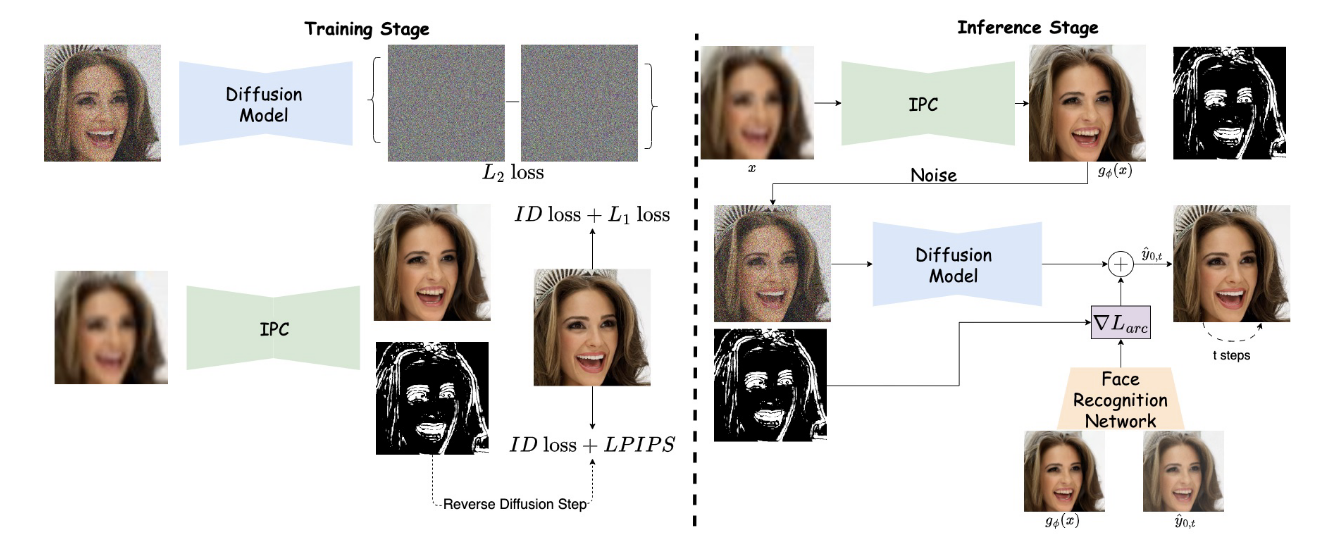 Diffuse and Restore: A Region-Adaptive Diffusion Model for Identity-Preserving Blind Face RestorationMaitreya Suin, Nithin Gopalakrishnan Nair, Chun Pong Lau, and 2 more authorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Mar 2024
Diffuse and Restore: A Region-Adaptive Diffusion Model for Identity-Preserving Blind Face RestorationMaitreya Suin, Nithin Gopalakrishnan Nair, Chun Pong Lau, and 2 more authorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Mar 2024Blind face restoration (BFR) from severely degraded face images in the wild is a highly ill-posed problem. Due to the complex unknown degradation, existing generative works typically struggle to restore realistic details when the input is of poor quality. Recently, diffusion-based approaches were successfully used for high-quality image synthesis. But, for BFR, maintaining a balance between the fidelity of the restored image and the reconstructed identity information is important. With this observation, we present a conditional diffusion-based framework for BFR. We alleviate the drawbacks of existing diffusion-based approaches and design a region-adaptive strategy. Specifically, we use an identity preserving conditioner network to recover the identity information from the input image and use that to guide the reverse diffusion process for important facial locations that contribute the most to the identity. This leads to a significant improvement in perceptual quality as well as face-recognition scores over existing GAN and diffusion-based restoration models.
@inproceedings{suin2024diffuse, title = {Diffuse and Restore: A Region-Adaptive Diffusion Model for Identity-Preserving Blind Face Restoration}, author = {Suin, Maitreya and Nair, Nithin Gopalakrishnan and Lau, Chun Pong and Patel, Vishal M and Chellappa, Rama}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, pages = {6343--6352}, year = {2024}, }
2023
- ICCV 2023
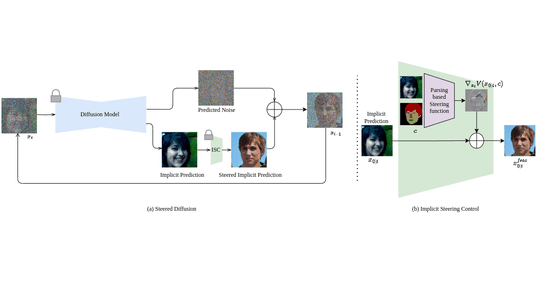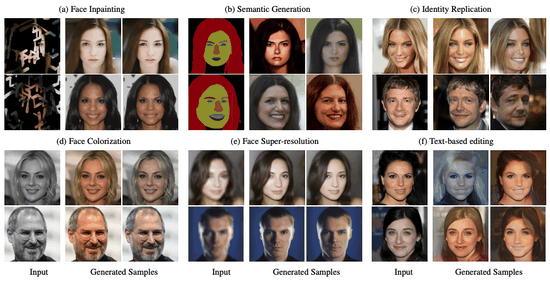 Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image SynthesisNithin Gopalakrishnan Nair, Anoop Cherian, Suhas Lohit, and 4 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2023
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image SynthesisNithin Gopalakrishnan Nair, Anoop Cherian, Suhas Lohit, and 4 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2023Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
@inproceedings{Nair_2023_ICCV, author = {Nair, Nithin Gopalakrishnan and Cherian, Anoop and Lohit, Suhas and Wang, Ye and Koike-Akino, Toshiaki and Patel, Vishal M. and Marks, Tim K.}, title = {Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, month = oct, year = {2023}, pages = {20850-20860}, selected = true, } - CVPR 2023
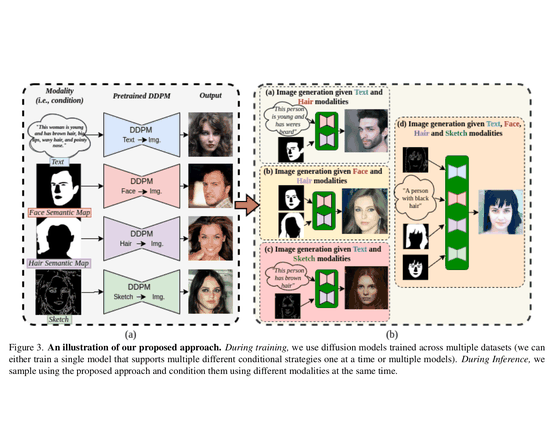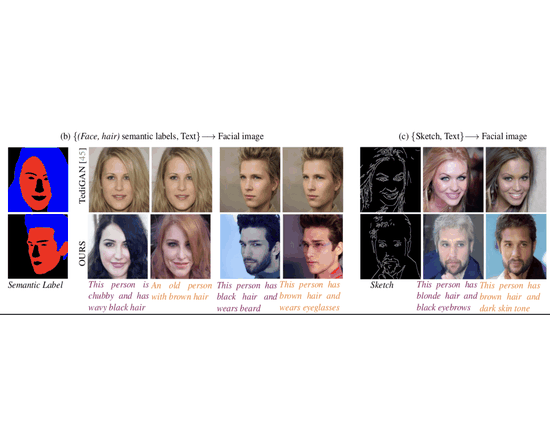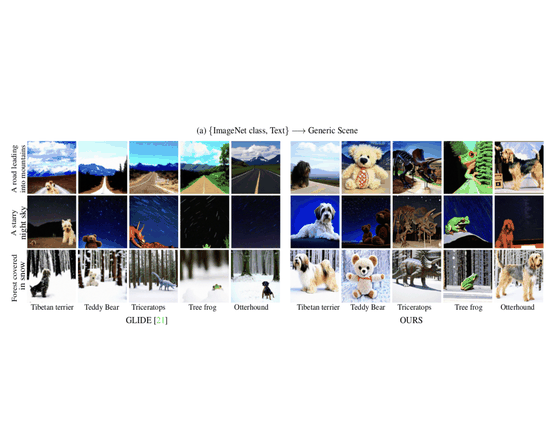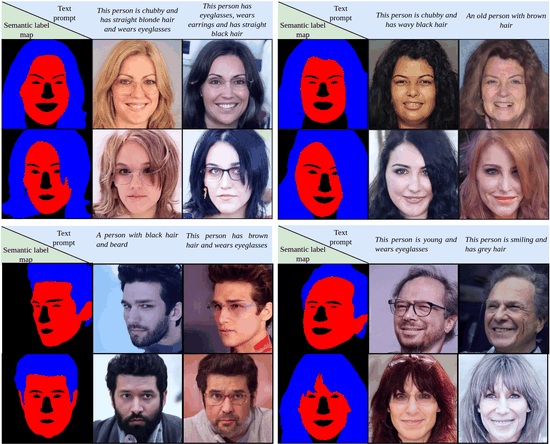 Unite and Conquer: Plug & Play Multi-Modal Synthesis Using Diffusion ModelsNithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and Vishal M PatelIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2023
Unite and Conquer: Plug & Play Multi-Modal Synthesis Using Diffusion ModelsNithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and Vishal M PatelIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2023Generating photos satisfying multiple constraints finds broad utility in the content creation industry. A key hurdle to accomplishing this task is the need for paired data consisting of all modalities (i.e., constraints) and their corresponding output. Moreover, existing methods need retraining using paired data across all modalities to introduce a new condition. This paper proposes a solution to this problem based on denoising diffusion probabilistic models (DDPMs). Our motivation for choosing diffusion models over other generative models comes from the flexible internal structure of diffusion models. Since each sampling step in the DDPM follows a Gaussian distribution, we show that there exists a closed-form solution for generating an image given various constraints. Our method can unite multiple diffusion models trained on multiple sub-tasks and conquer the combined task through our proposed sampling This CVPR paper is the Open Access version, provided by the Computer Vision Foundation. Except for this watermark, it is identical to the accepted version; the final published version of the proceedings is available on IEEE Xplore. 6070 strategy. We also introduce a novel reliability parameter that allows using different off-the-shelf diffusion models trained across various datasets during sampling time alone to guide it to the desired outcome satisfying multiple constraints. We perform experiments on various standard multimodal tasks to demonstrate the effectiveness of our approach. More details can be found at: https://nithingk.github.io/projectpages/Multidiff
@inproceedings{nair2023unite, title = {Unite and Conquer: Plug \& Play Multi-Modal Synthesis Using Diffusion Models}, author = {Nair, Nithin Gopalakrishnan and Bandara, Wele Gedara Chaminda and Patel, Vishal M}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, month = jun, pages = {6070--6079}, year = {2023}, selected = true, } - FG 2023
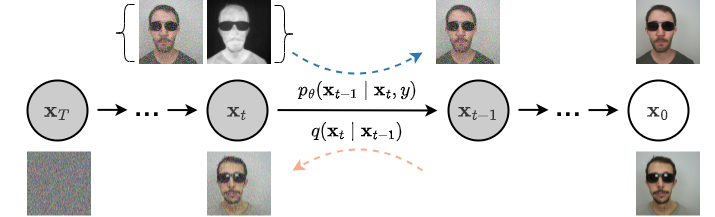 T2V-DDPM: Thermal to Visible Face Translation using Denoising Diffusion Probabilistic ModelsNithin Gopalakrishnan Nair and Vishal M PatelIn 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), Jan 2023
T2V-DDPM: Thermal to Visible Face Translation using Denoising Diffusion Probabilistic ModelsNithin Gopalakrishnan Nair and Vishal M PatelIn 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), Jan 2023Modern-day surveillance systems perform person recognition using deep learning-based face verification networks. Most state-of-the-art facial verification systems are trained using visible spectrum images. But, acquiring images in the visible spectrum is impractical in scenarios of low-light and nighttime conditions, and often images are captured in an alternate domain such as the thermal infrared domain. Facial verification in thermal images is often performed after retrieving the corresponding visible domain images. This is a well-established problem often known as the Thermal-to-Visible (T2V) image translation. In this paper, we propose a Denoising Diffusion Probabilistic Model (DDPM) based solution for T2V translation specifically for facial images. During training, the model learns the conditional distribution of visible facial images given their corresponding thermal image through the diffusion process. During inference, the visible domain image is obtained by starting from Gaussian noise and performing denoising repeatedly. The existing inference process for DDPMs is stochastic and time-consuming. Hence, we propose a novel inference strategy for speeding up the inference time of DDPMs, specifically for the problem of T2V image translation. We achieve the state-of-the-art results on multiple datasets. The code and pretrained models are publically available at http://github.com/Nithin-GK/T2V-DDPM
@inproceedings{nair2023t2v, title = {T2V-DDPM: Thermal to Visible Face Translation using Denoising Diffusion Probabilistic Models}, author = {Nair, Nithin Gopalakrishnan and Patel, Vishal M}, booktitle = {2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG)}, pages = {1--7}, month = jan, year = {2023}, organization = {IEEE}, } - WACV 2023
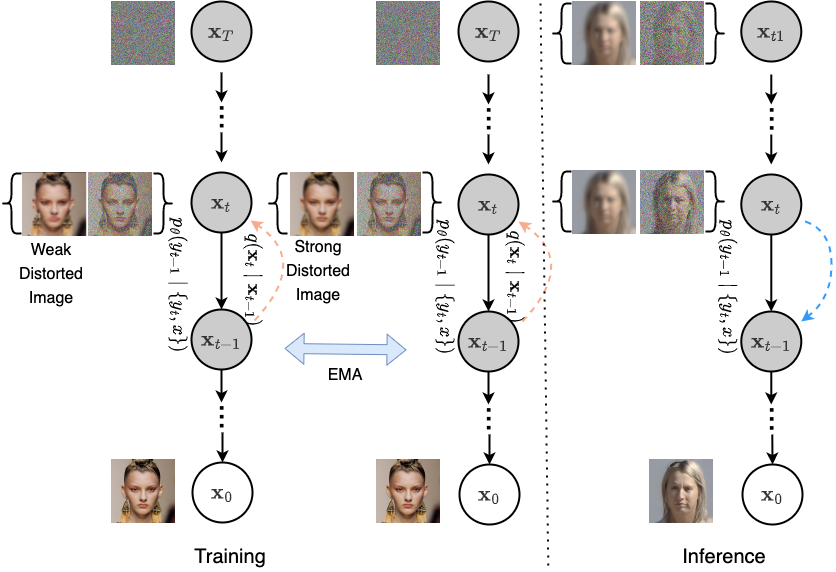 AT-DDPM: Restoring Faces Degraded by Atmospheric Turbulence Using Denoising Diffusion Probabilistic ModelsNithin Gopalakrishnan Nair, Kangfu Mei, and Vishal M. PatelIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Jan 2023
AT-DDPM: Restoring Faces Degraded by Atmospheric Turbulence Using Denoising Diffusion Probabilistic ModelsNithin Gopalakrishnan Nair, Kangfu Mei, and Vishal M. PatelIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Jan 2023Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversionbased, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models are publically available at http://github.com/Nithin-GK/AT-DDPM
@inproceedings{Nair_2023_WACV, author = {Nair, Nithin Gopalakrishnan and Mei, Kangfu and Patel, Vishal M.}, title = {AT-DDPM: Restoring Faces Degraded by Atmospheric Turbulence Using Denoising Diffusion Probabilistic Models}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, month = jan, year = {2023}, pages = {3434-3443}, } - GRSL 2023
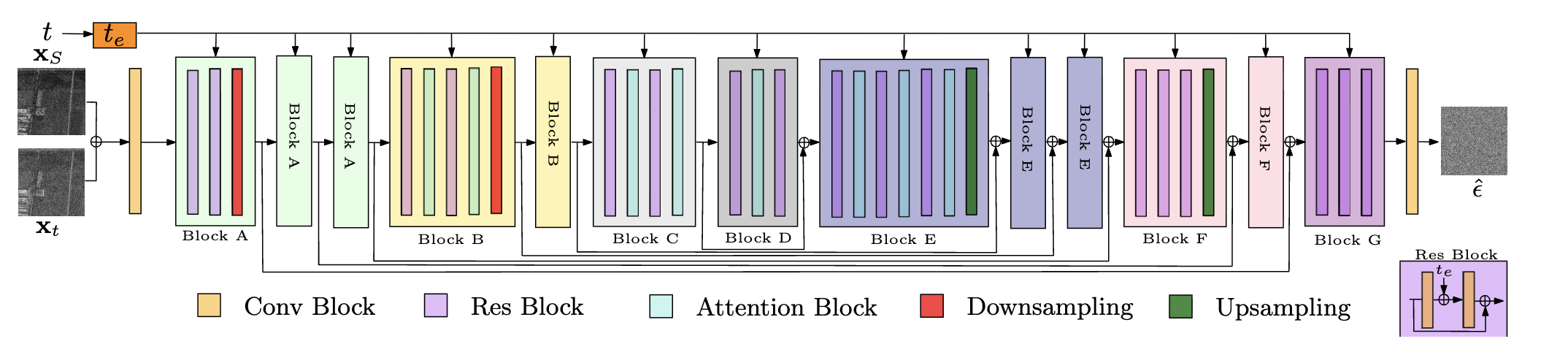 Sar despeckling using a denoising diffusion probabilistic modelMalsha V Perera, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and 1 more authorIEEE Geoscience and Remote Sensing Letters, Jan 2023
Sar despeckling using a denoising diffusion probabilistic modelMalsha V Perera, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and 1 more authorIEEE Geoscience and Remote Sensing Letters, Jan 2023Speckle is a type of multiplicative noise that affects all coherent imaging modalities including synthetic aperture radar (SAR) images. The presence of speckle degrades the image quality and can adversely affect the performance of SAR image applications such as automatic target recognition and change detection. Thus, SAR despeckling is an important problem in remote sensing. In this letter, we introduce SAR-DDPM, a denoising diffusion probabilistic model for SAR despeckling. The proposed method uses a Markov chain that transforms clean images into white Gaussian noise by successively adding random noise. The despeckled image is obtained through a reverse process that predicts the added noise iteratively, using a noise predictor conditioned on the speckled image. In addition, we propose a new inference strategy based on cycle spinning to improve the despeckling performance. Our experiments on both synthetic and real SAR images demonstrate that the proposed method leads to significant improvements in both quantitative and qualitative results over the state-of-the-art despeckling methods. The code is available at: https://github.com/malshaV/SAR_DDPM
@article{perera2023sar, title = {Sar despeckling using a denoising diffusion probabilistic model}, author = {Perera, Malsha V and Nair, Nithin Gopalakrishnan and Bandara, Wele Gedara Chaminda and Patel, Vishal M}, journal = {IEEE Geoscience and Remote Sensing Letters}, year = {2023}, publisher = {IEEE}, }
2022
- ICIP 2022
 A Comparison of Different Atmospheric Turbulence Simulation Methods for Image RestorationNithin Gopalakrishnan Nair, Kangfu Mei, and Vishal M. PatelIn 2022 IEEE International Conference on Image Processing (ICIP), Jan 2022
A Comparison of Different Atmospheric Turbulence Simulation Methods for Image RestorationNithin Gopalakrishnan Nair, Kangfu Mei, and Vishal M. PatelIn 2022 IEEE International Conference on Image Processing (ICIP), Jan 2022Atmospheric turbulence deteriorates the quality of images captured by long-range imaging systems by introducing blur and geometric distortions to the captured scene. This leads to a drastic drop in performance when computer vision algorithms like object/face recognition and detection are performed on these images. In recent years, various deep learning-based atmospheric turbulence mitigation methods have been proposed in the literature. These methods are often trained using synthetically generated images and tested on real-world images. Hence, the performance of these restoration methods depends on the type of simulation used for training the network. In this paper, we systematically evaluate the effectiveness of various turbulence simulation methods on image restoration. In particular, we evaluate the performance of two stateor-the-art restoration networks using six simulations method on a real-world LRFID dataset consisting of face images degraded by turbulence. This paper will provide guidance to the researchers and practitioners working in this field to choose the suitable data generation models for training deep models for turbulence mitigation. The implementation codes for the simulation methods, source codes for the networks and the pre-trained models are available at https://github.com/Nithin-GK/Turbulence-Simulations
@inproceedings{9897969, author = {Gopalakrishnan Nair, Nithin and Mei, Kangfu and Patel, Vishal M.}, booktitle = {2022 IEEE International Conference on Image Processing (ICIP)}, title = {A Comparison of Different Atmospheric Turbulence Simulation Methods for Image Restoration}, year = {2022}, volume = {}, number = {}, pages = {3386-3390}, doi = {10.1109/ICIP46576.2022.9897969}, } - ICIP 2022
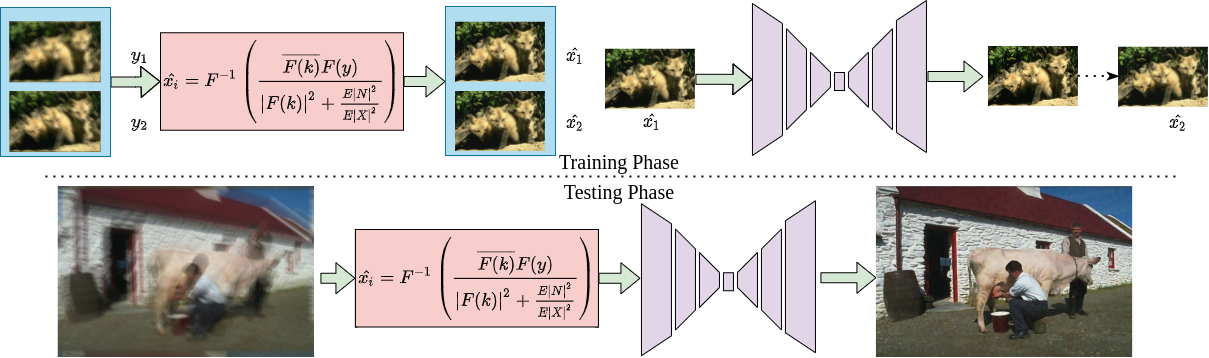 NBD-GAP: Non-Blind Image Deblurring without Clean Target ImagesNithin Gopalakrishnan Nair, Rajeev Yasarla, and Vishal M. PatelIn 2022 IEEE International Conference on Image Processing (ICIP), Jan 2022
NBD-GAP: Non-Blind Image Deblurring without Clean Target ImagesNithin Gopalakrishnan Nair, Rajeev Yasarla, and Vishal M. PatelIn 2022 IEEE International Conference on Image Processing (ICIP), Jan 2022In recent years, deep neural network-based restoration methods have achieved state-of-the-art results in various image deblurring tasks. However, one major drawback of deep learning-based deblurring networks is that large amounts of blurry-clean image pairs are required for training to achieve good performance. Moreover, deep networks often fail to perform well when the blurry images and the blur kernels during testing are very different from the ones used during training. This happens mainly because of the overfitting of the network parameters on the training data. In this work, we present a method that addresses these issues. We view the non-blind image deblurring problem as a denoising problem. To do so, we perform Wiener filtering on a pair of blurry images with the corresponding blur kernels. This results in a pair of images with colored noise. Hence, the deblurring problem is translated into a denoising problem. We then solve the denoising problem without using explicit clean target images. Extensive experiments are conducted to show that our method achieves results that are on par to the state-of-the-art non-blind deblurring works.
@inproceedings{9897543, author = {Gopalakrishnan Nair, Nithin and Yasarla, Rajeev and Patel, Vishal M.}, booktitle = {2022 IEEE International Conference on Image Processing (ICIP)}, title = {NBD-GAP: Non-Blind Image Deblurring without Clean Target Images}, year = {2022}, volume = {}, number = {}, pages = {3431-3435}, doi = {10.1109/ICIP46576.2022.9897543}, }
2021
- TIP 2021
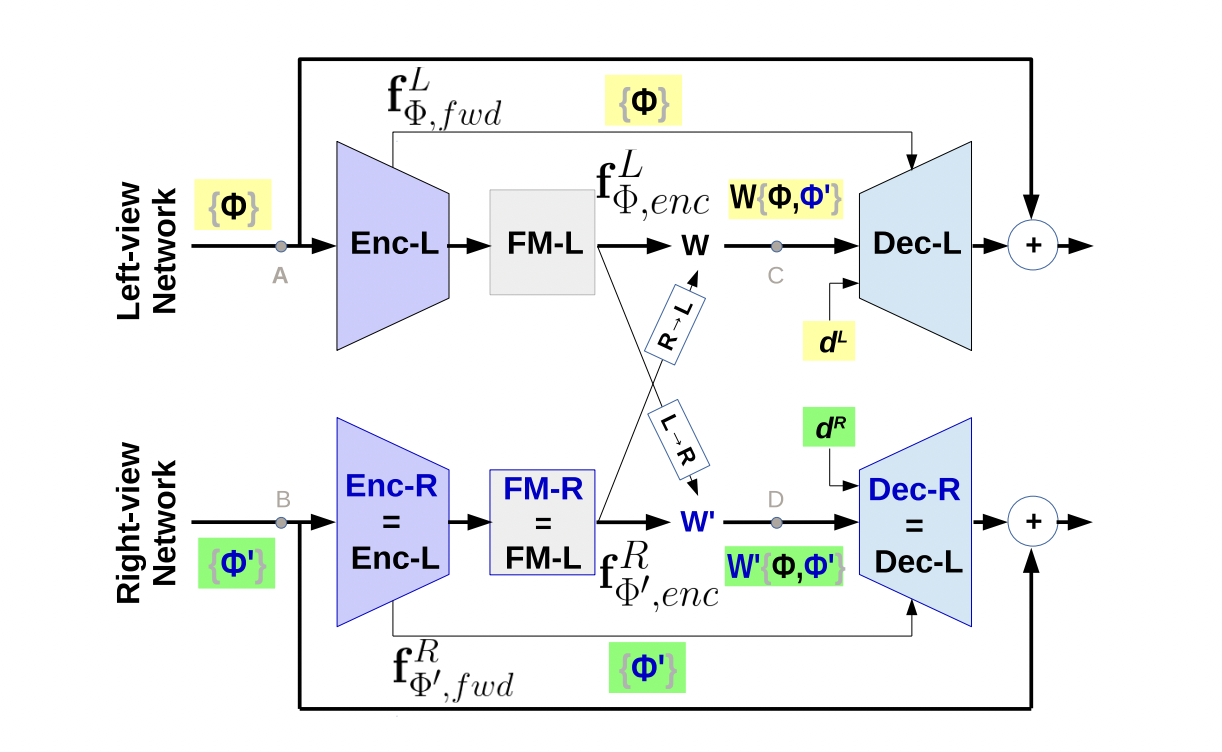 Deep dynamic scene deblurring for unconstrained dual-lens camerasMR Mahesh Mohan, GK Nithin, and AN RajagopalanIEEE Transactions on Image Processing, Jan 2021
Deep dynamic scene deblurring for unconstrained dual-lens camerasMR Mahesh Mohan, GK Nithin, and AN RajagopalanIEEE Transactions on Image Processing, Jan 2021Dual-lens (DL) cameras capture depth information, and hence enable several important vision applications. Most present-day DL cameras employ unconstrained settings in the two views in order to support extended functionalities. But a natural hindrance to their working is the ubiquitous motion blur encountered due to camera motion, object motion, or both. However, there exists not a single work for the prospective unconstrained DL cameras that addresses this problem (so called dynamic scene deblurring). Due to the unconstrained settings, degradations in the two views need not be the same, and consequently, naive deblurring approaches produce inconsistent left-right views and disrupt scene-consistent disparities. In this paper, we address this problem using Deep Learning and make three important contributions. First, we address the root cause of view-inconsistency in standard deblurring architectures using a Coherent Fusion Module. Second, we address an inherent problem in unconstrained DL deblurring that disrupts scene-consistent disparities by introducing a memory-efficient Adaptive Scale-space Approach. This signal processing formulation allows accommodation of different image-scales in the same network without increasing the number of parameters. Finally, we propose a module to address the Space-variant and Image-dependent nature of dynamic scene blur. We experimentally show that our proposed techniques have substantial practical merit.
@article{mohan2021deep, title = {Deep dynamic scene deblurring for unconstrained dual-lens cameras}, author = {Mohan, MR Mahesh and Nithin, GK and Rajagopalan, AN}, journal = {IEEE Transactions on Image Processing}, volume = {30}, pages = {4479--4491}, year = {2021}, publisher = {IEEE}, } - ICIP 2021
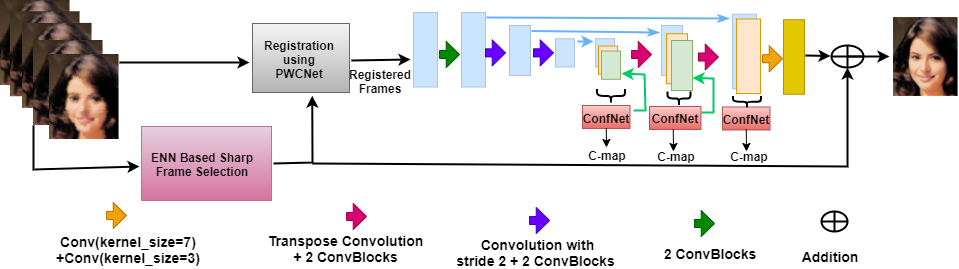 Confidence Guided Network For Atmospheric Turbulence MitigationNithin Gopalakrishnan Nair and Vishal M. PatelIn 2021 IEEE International Conference on Image Processing (ICIP), Jan 2021
Confidence Guided Network For Atmospheric Turbulence MitigationNithin Gopalakrishnan Nair and Vishal M. PatelIn 2021 IEEE International Conference on Image Processing (ICIP), Jan 2021Atmospheric turbulence can adversely affect the quality of images or videos captured by long range imaging systems. Turbulence causes both geometric and blur distortions in images which in turn results in poor performance of the subsequent computer vision algorithms like recognition and detection. Existing methods for atmospheric turbulence mitigation use registration and deconvolution schemes to remove degradations. In this paper, we present a deep learning-based solution in which Effective Nearest Neighbors (ENN) based method is used for registration and an uncertainty-based network is used for restoration. We perform qualitative and quantitative comparisons using synthetic and real-world datasets to show the significance of our work.
@inproceedings{9506125, author = {Nair, Nithin Gopalakrishnan and Patel, Vishal M.}, booktitle = {2021 IEEE International Conference on Image Processing (ICIP)}, title = {Confidence Guided Network For Atmospheric Turbulence Mitigation}, year = {2021}, volume = {}, number = {}, pages = {1359-1363}, doi = {10.1109/ICIP42928.2021.9506125}, }